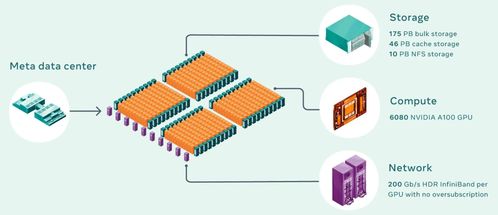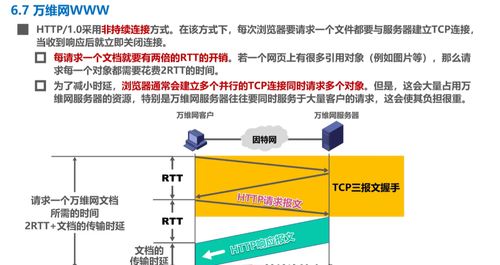
計算機網(wǎng)絡是現(xiàn)代信息社會的基石,其技術開發(fā)是推動數(shù)字化轉(zhuǎn)型的核心驅(qū)動力。一個成功的網(wǎng)絡技術開發(fā)項目,不僅需要深入理解網(wǎng)絡的基本原理,更需將性能指標作為設計與優(yōu)化的核心標尺。
一、計算機網(wǎng)絡概述:系統(tǒng)的視角
計算機網(wǎng)絡可定義為通過通信線路與設備,將地理位置分散、具有獨立功能的多個計算機系統(tǒng)互聯(lián)起來,在功能完善的網(wǎng)絡軟件(協(xié)議)管理下,實現(xiàn)資源共享和信息傳遞的系統(tǒng)。其發(fā)展經(jīng)歷了從面向終端的單機系統(tǒng),到以資源共享為目的的ARPANET,再到標準化、全球互聯(lián)的Internet階段。現(xiàn)代網(wǎng)絡呈現(xiàn)出高速化、無線化、智能化與融合化的趨勢。從邏輯上,網(wǎng)絡通常被劃分為資源子網(wǎng)(負責數(shù)據(jù)處理)和通信子網(wǎng)(負責數(shù)據(jù)通信);從功能上,則普遍采用分層模型,如OSI七層參考模型與實際廣泛應用的TCP/IP四層模型,它們將復雜的通信過程分解為相對獨立的模塊,是技術開發(fā)中協(xié)議設計與實現(xiàn)的根本框架。
二、性能指標:技術開發(fā)的度量衡與目標
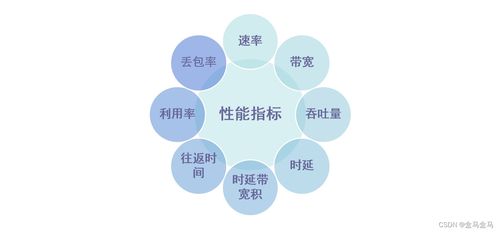
性能指標是衡量網(wǎng)絡技術優(yōu)劣、指導開發(fā)方向的量化標準。核心指標包括:
- 速率與帶寬:速率指數(shù)據(jù)的實際傳輸速率(bps),帶寬指信道理論上能通過的最高數(shù)據(jù)率。提升速率與有效利用帶寬是物理層、數(shù)據(jù)鏈路層乃至應用層開發(fā)永恒的主題。
- 時延:數(shù)據(jù)從網(wǎng)絡一端傳送到另一端所需的時間,包括發(fā)送時延、傳播時延、處理時延和排隊時延。低時延是實時應用(如音視頻通話、在線游戲、工業(yè)控制)開發(fā)的關鍵訴求。
- 時延帶寬積:表征信道可容納的比特數(shù)量,指導開發(fā)者理解管道容量。
- 吞吐量:單位時間內(nèi)通過某個網(wǎng)絡的實際數(shù)據(jù)量。優(yōu)化協(xié)議與算法以提升有效吞吐量,是網(wǎng)絡開發(fā)的核心挑戰(zhàn)之一。
- 丟包率與誤碼率:衡量網(wǎng)絡可靠性的重要指標。在不可靠的物理介質(zhì)(如無線網(wǎng)絡)上開發(fā)高可靠服務,需要依賴TCP等傳輸層協(xié)議的重傳、糾錯機制。
- 可用性與可擴展性:指網(wǎng)絡系統(tǒng)持續(xù)提供服務的能力及適應規(guī)模增長的能力,這直接關系到系統(tǒng)架構(gòu)的設計。
這些指標并非孤立,往往存在權衡(Trade-off)。例如,追求極低時延可能導致吞吐量下降;增加冗余以提高可靠性可能犧牲效率。優(yōu)秀的技術開發(fā)正是在這些權衡中尋找最佳平衡點。
三、以性能為導向的計算機網(wǎng)絡技術開發(fā)實踐
將概述與性能指標融入開發(fā)實踐,需貫穿于從協(xié)議設計到系統(tǒng)實現(xiàn)的各個環(huán)節(jié):
- 協(xié)議設計與優(yōu)化:這是網(wǎng)絡開發(fā)的核心。例如,為適應高帶寬、高時延乘積網(wǎng)絡,開發(fā)了新的擁塞控制算法(如BBR);為滿足物聯(lián)網(wǎng)低功耗需求,設計了輕量級協(xié)議CoAP;為提高傳輸效率,出現(xiàn)了QUIC協(xié)議以替代TCP+TLS的組合。開發(fā)中需針對特定性能目標(如降低時延、減少握手次數(shù))進行創(chuàng)新。
- 網(wǎng)絡編程與API開發(fā):開發(fā)者利用Socket API等接口進行網(wǎng)絡應用開發(fā)。高性能網(wǎng)絡編程需深入理解非阻塞I/O、多路復用(如epoll/kqueue)、零拷貝等技術,以最小化處理時延,提升并發(fā)吞吐量。
- 網(wǎng)絡設備與系統(tǒng)開發(fā):包括路由器、交換機、防火墻等設備的軟硬件開發(fā)。這涉及高速分組轉(zhuǎn)發(fā)、流量調(diào)度、 QoS(服務質(zhì)量)保證等,直接決定網(wǎng)絡核心層的性能上限。例如,利用可編程芯片(如P4)和智能網(wǎng)卡,可以實現(xiàn)更靈活、高性能的數(shù)據(jù)平面功能。
- 網(wǎng)絡管理與運維工具開發(fā):開發(fā)監(jiān)控、分析、配置工具,以實時測量帶寬、時延、丟包率等指標,實現(xiàn)故障快速定位與性能優(yōu)化,保障網(wǎng)絡SLA(服務等級協(xié)議)。
- 新興技術領域的開發(fā):在軟件定義網(wǎng)絡(SDN)中,通過分離控制平面與數(shù)據(jù)平面,實現(xiàn)網(wǎng)絡的集中、靈活管控;在網(wǎng)絡功能虛擬化(NFV)中,將網(wǎng)絡功能軟件化,提升部署彈性與資源利用率;在5G/6G、邊緣計算中,開發(fā)滿足超高可靠低時延通信(URLLC)和海量機器通信(mMTC)需求的新技術與協(xié)議棧。
計算機網(wǎng)絡技術開發(fā)是一個動態(tài)、多維的工程領域。堅實的理論基礎(概述)提供了系統(tǒng)的認知框架,而明確的性能指標則為開發(fā)工作提供了可衡量、可優(yōu)化的具體目標。隨著人工智能、量子通信等技術的融合,網(wǎng)絡技術開發(fā)將持續(xù)面臨新的挑戰(zhàn)與機遇,但其核心——在復雜的系統(tǒng)約束下,高效、可靠、安全地實現(xiàn)數(shù)據(jù)流通——將始終不變。開發(fā)者唯有深刻理解網(wǎng)絡之“道”(原理與指標),方能精湛掌握開發(fā)之“術”,創(chuàng)造出更卓越的網(wǎng)絡產(chǎn)品與服務。